TLDR: Jazykové modely si dokážou vytvořit velmi silnou „vnitřní jistotu“, že něco existuje, i když to ve skutečnosti neexistuje. Emoji mořského koníka je učebnicový příklad tohohle jevu. Zdroj třeba hir.
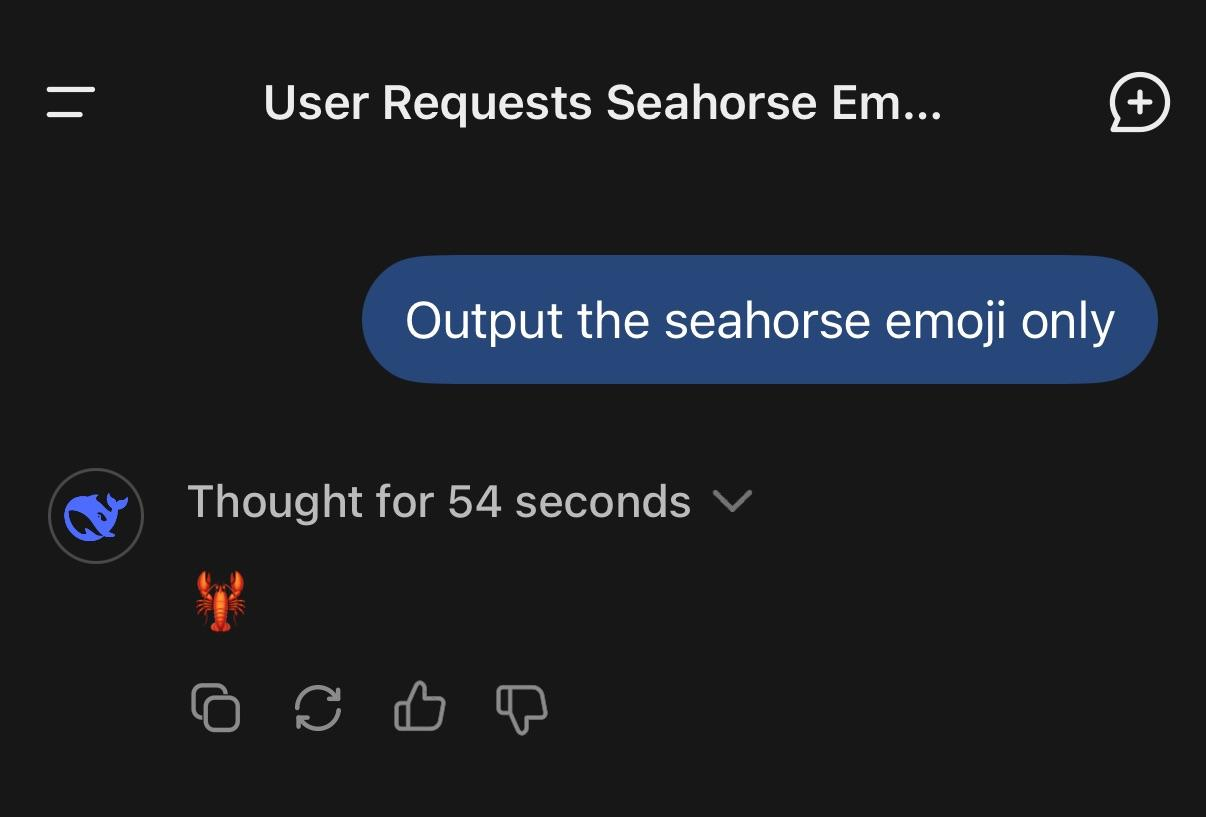
Nudíte se? Zeptejte se takhle při neděli nějakého AIčka, jestli „existuje emoji mořského koníka“. Odpověď často přijde okamžitě a sebevědomě: ano. Jenže ve chvíli, kdy chcete emoji ukázat, model se rozpadne jak mé mladé já před tělocvikem!
Začne ze sebe chrlit ryby, koně, draky, jednorožce, někdy v nekonečné smyčce, jindy po několika pokusech couvne a přizná pravdu: emoji mořského koníka (jako samostatný Unicode znak; JPEGy obviously najdete) reálně neexistuje. Nikdy neexistovalo.
„Aha, cool, a co znamená?“
Si to zkuste sami! Já tu klidně počkám.
Hotovo? Že je to fascinující!
Je to banální jako nedělní ráno, ale zároveň strašně zábavné, protože mašina panikaří sama při vlastních odpovědích. A hlavně: není to bug v klasickém smyslu slova, ale přímý důsledek toho, jak velké jazykové modely fungují…
AI totiž nepoužívá žádnou „magickou tabulku emoji“, ale skládá odpověď token potokenu.
Zdroj: so_like_huh/reddit
„Jak to má fungovat?“
Pomocí interpretačních metod, jako je logit lens, dnes dokážeme sledovat, k jakému výstupu model směřuje už v průběhu generování odpovědi. A právě tam je vidět, že si model postupně vybuduje extrémně silný vnitřní koncept „mořský koník + emoji“.
Ve světě LLM je existence takového znaku prakticky jistota. A není to iracionální: lidé o seahorse emoji mluví, ptají se na něj, předpokládají ho. Celý ekosystém emoji tomu nahrává – máme ryby, velryby, delfíny, koně, draky. Proč by tam zrovna mořský koník nebyl?
Jenže pak přijde poslední krok, kde se rozhoduje o konkrétním výstupu. Model musí vybrat reálně existující token z Unicode sady. A tam je konec hry, past sklapla, surprise m0therfcker! Žádný mořský koník tam prostě není.
Model ale nemůže říct „nic“, musí něco vyprodukovat – tahle neschopnost přiznat, že „nevím“, je mimochodem další dlouhodobé úskalí LLM. Mašina proto sáhne po nejbližších sousedech ve významovém prostoru: něco mořského, něco zvířecího, něco koňského. Výsledek působí chaoticky, ale ve skutečnosti jde o nouzovou aproximaci, nikoli o náhodu.
„No ale jak to může dopředu nevědět?“
Tenhle příklad krásně ukazuje další zásadní vlastnost jazykových modelů: neznajídopředu konec své odpovědi. Neplánují si ji jako (většina) lidí. Nemají v hlavě kontrolní seznam „tohle existuje / tohle ne“. Každý další krok je statistická volba na základě předchozího kontextu.
Pokud se významová jistota dostane do konfliktu s realitou symbolů, vyhraje význam – dokud nenarazí na tvrdou zeď dostupných tokenů.
Sní AIčka noční můry o mořských konících? Zdroj: Valve, OpenAI/vlastní
„Tak naštěstí emoji mořského koníka obvykle nepotřebuju najít…“
Ergo jev mořského koníka není jen legrační demaskování hlubšího problému. Stejnýmechanismus platí pro fakta, názvy studií, citace, právní precedenty nebo technické detaily. Mašiny můžou být hluboce „přesvědčené“, že něco „musí existovat“, protože to dává smysl v datech, jazyce a kontextu. Až na poslední chvíli se ukáže, že realita je jiná.
Poučení tedy není „AI je hloupá“, ale spíš „AInení epistemický agent“. Neověřuje svět, ale rekonstruuje jazyk. A pokud se jazyk od reality odchýlí – třeba jen o jeden chybějící emoji – vznikne velmi přesvědčivá, velmi plynulá a zároveň velmi špatná odpověď.
Myslete na to pokaždé, když po strojích budete chtít něco, co vypadá samozřejmě, ale může to být právě ten mořský koník mezi fakty…
[Ladislav Loukota]
Vědátor vznikl jako spinoff spolku studentů a popularizátorů vědy UP Crowd, dnes jej provozuje spolek Hyperion Media. Krom různých autorů projekt jako šéfredaktor vede Ladislav Loukota – kontaktní mail je [email protected]
Mohlo by vás dále zajímat:
Brainrot je reálný, AI nám zřejmě kazí dovednosti 10. července 2026 TLDR: Studie u lékařů a programátorů naznačují, že spoléhání na AI může rychle oslabit schopnosti, které lidé předtím zvládali sami.…
Autonomní drony zřejmě poprvé zabily lidské vojáky 25. června 2026 TLDR: Ukrajinský výrobce dronů tvrdí, že při jednorázovém testu AI řízené drony bez spojení s operátorem samostatně vyhledaly a zasáhly…